Surgiu uma demanda por parte de um cliente: eles receberiam arquivos de parceiros através de SFTP e havia a necessidade de que esses arquivos subissem para o SharePoint. A solução foi utilizar um servidor Windows com OpenSSH e OneDrive para fazer essa integração.
Uma conta Microsoft dedicada foi criada para conectar o servidor ao OneDrive, digamos sftp@exemplo.com. O site e a biblioteca no SharePoint foram criados e foi adicionado um atalho para a biblioteca ao OneDrive dessa conta.
O OneDrive foi configurado através de uma outra conta local criada sem privilégios de administrador, com nome de sftp. O atalho para a biblioteca “sftp-1drv” aparece como algo do tipo C:\Users\sftp\OneDrive \sftp-1drv.
Então, o serviço de SSH é instalado através do PowerShell com:
Cada usuário do SFTP deve ter acesso à sua própria pasta e o acesso a outras deve ser restringido.
Nenhum dos usuários deve ter acesso ao prompt de comando através de SSH.
Por segurança, o acesso por senha deve ser impedido, permitindo apenas o acesso através de par de chaves pública-privada.
Os dois primeiros podem ser alcançados adicionando a seguinte configuração ao arquivo de configuração do OpenSSH localizado em C:\ProgramData\ssh\sshd_config:
Match Group "SFTP Users"
ChrootDirectory "C:\Users\sftp\OneDrive\sftp-1drv\%u"
ForceCommand internal-sftp
AllowTcpForwarding no
Onde %u é o nome de usuário e “SFTP Users” é o grupo ao qual os usuários pertencem.
O grupo pode ser criado com:
C:\Windows\System32> net localgroup "SFTP Users" /add
O acesso através de senha pode ser desabilitado configurando o seguinte parêmetro:
PasswordAuthentication no
Após configurado, marque o serviço para iniciar com o sistema e inicie-o:
Agora, usuários precisam ser criados. O que precisa ser feito:
Criar o usuário;
Incluí-lo ao grupo SFTP Users;
Criar a pasta do usuário no SharePoint;
Gerar as chaves RSA ou Ed25519 para acesso ao SFTP;
Permitir o acesso ao usuário através do par de chaves criado;
Copiar a chave privada para o SharePoint para que a chave seja passada ao usuário.
Para copiar a chave privada para o SharePoint, foi criada uma pasta separada para isso em C:\Users\sftp\OneDrive\sftp-1drv\_chaves_sftp.
O procedimento então foi parcialmente automatizado através de um batch script simples que recebe o nome de usuário como argumento:
if not exist "%userprofile%\.ssh" (
mkdir "%userprofile%\.ssh"
)
net user "%1" /add
net user "%1" $enha@12321
net localgroup "SFTP Users" "%1" /add
:: a linha abaixo é necessária para que a pasta do perfil do usuário seja criada pelo sistema
runas /user:"%1" "cmd /c exit"
mkdir "C:\Users\sftp\OneDrive\sftp-1drv\%1"
ssh-keygen -t ed25519 -f "%userprofile%\.ssh\%1" -N ""
type "%userprofile%\.ssh\%1" > "C:\Users\sftp\OneDrive\sftp-1drv\_chaves_sftp\%1.pem"
mkdir "C:\Users\%1\.ssh"
type "%userprofile%\.ssh\%1.pub" > "C:\Users\%1\.ssh\authorized_keys"
O script cria o usuário com a senha $enha@12321 e pede essa senha para executar o cmd como o novo usuário criado. Isso é feito porque o Windows precisa de um primeiro login interativo para criar a pasta do perfil do usuário e é necessário para que seja criado o arquivo authorized_keys no perfil do usuário.
Na execução do script para criação de novos usuário, a pasta é criada e a chave fica acessível através do OneDrive, bastando baixar a chave e fazer o acesso via SFTP.
Por padrão, as máquinas virtuais do Proxmox se conectam a uma bridge ligada à interface física do servidor. Dessa forma, todas as máquinas virtuais aparecem como máquinas reais na rede física onde o servidor está conectado.
Idealmente, as máquinas virtuais com portas expostas para a internet estariam isoladas da rede principal, mas como o roteador em uso é um roteador de uso doméstico, sem a opção de criação de VLAN ou atribuição de redes diferentes a interfaces diferentes, uma alternativa se apresentou viável: instalar um firewall como máquina virtual no Proxmox e fazer com que as máquinas virtuais se conectem a ele em vez de diretamente na rede física.
Para o firewall, temos algumas opções de sistema operacional, as mais notáveis de código livre sendo OPNsense e pfSense. O OPNsense é um fork do pfSense, que é um fork do m0n0wall. Eles são baseados no FreeBSD. OPNsense surgiu como um fork do pfSense em grande parte por uma questão de licenciamento, sendo distribuído sob a licença simplificada BSD, e é o firewall utilizado aqui.
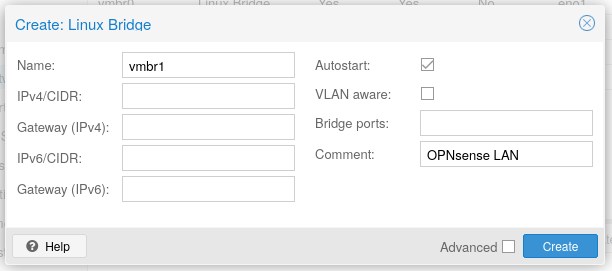
Antes de criar a máquina virtual, precisamos criar pelo menos uma bridge no servidor Proxmox para a LAN do OPNsense, a qual ficarão conectadas as máquinas virtuais. A bridgevmbr0 existente no Proxmox vai ser utilizada para a WAN, conectando o OPNsense à LAN física. Para isso, no Proxmox, selecione seu servidor > System > Network e crie a bridge, dando apenas um nome.
Após criada, aplique as configurações.
Alternativamente, pelo terminal do Proxmox, adicione a bridge ao arquivo /etc/network/interfaces:
auto vmbr1
iface vmbr1 inet manual
bridge-ports none
bridge-stp off
bridge-fd 0
# OPNsense LAN
auto vmbr2
iface vmbr2 inet manual
bridge-ports none
bridge-stp off
bridge-fd 0
# OPNsense LAN2
Vale reparar que outras bridges podem ser criadas e atribuídas a uma interface de rede na máquina virtual. Eu decidi criar duas.
Após editado o arquivo, use o seguinte comando para aplicar a configuração:
# ifreload -a
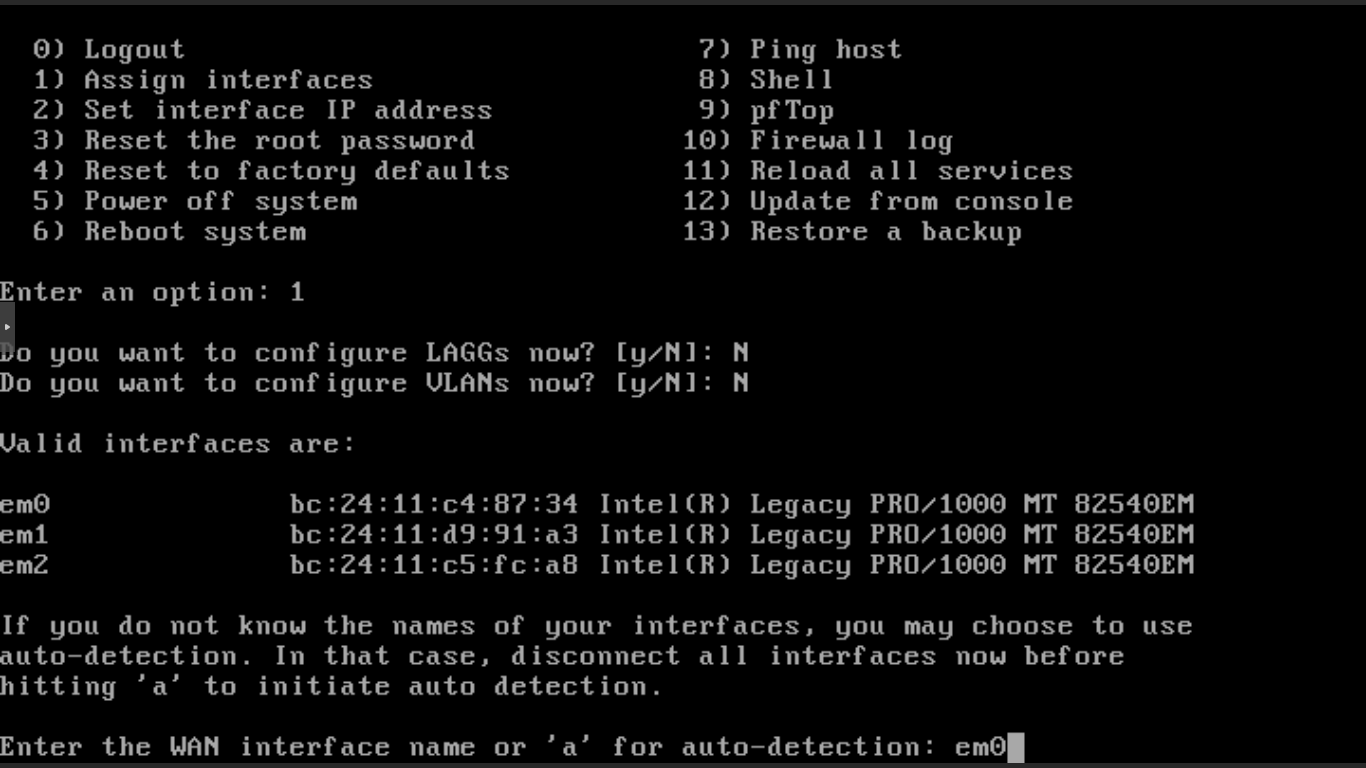
Finalizada a criação das bridges, crie a máquina virtual, adicione as interfaces de rede que desejar, inicie e instale o OPNsense. Ao finalizar, reinicie e atribua às interfaces o uso como WAN ou LAN – e opcionalmente OPT1, OPT2, etc.
Feito isso, atribua um endereço IP à elas conforme necessário. Nesse caso, a WAN permaneceu em DHCP e a LAN e OPT1 foram configuradas com IP estático – e ativado o servidor DHCP para a rede.
Então, você já pode alterar a bridge a qual estão conectadas as interfaces de rede das máquinas virtuais, e o OPNsense já deve estar acessível via web através da LAN virtual. No entanto, ele ainda não está acessível através da WAN (a LAN física). Para isso, são necessárias três configurações:
Vá em Interfaces > [WAN] e desabilite a caixa “Block private networks”.
Vá em Firewall > Settings > Advanced e habilite a caixa “Disable reply-to on WAN rules”.
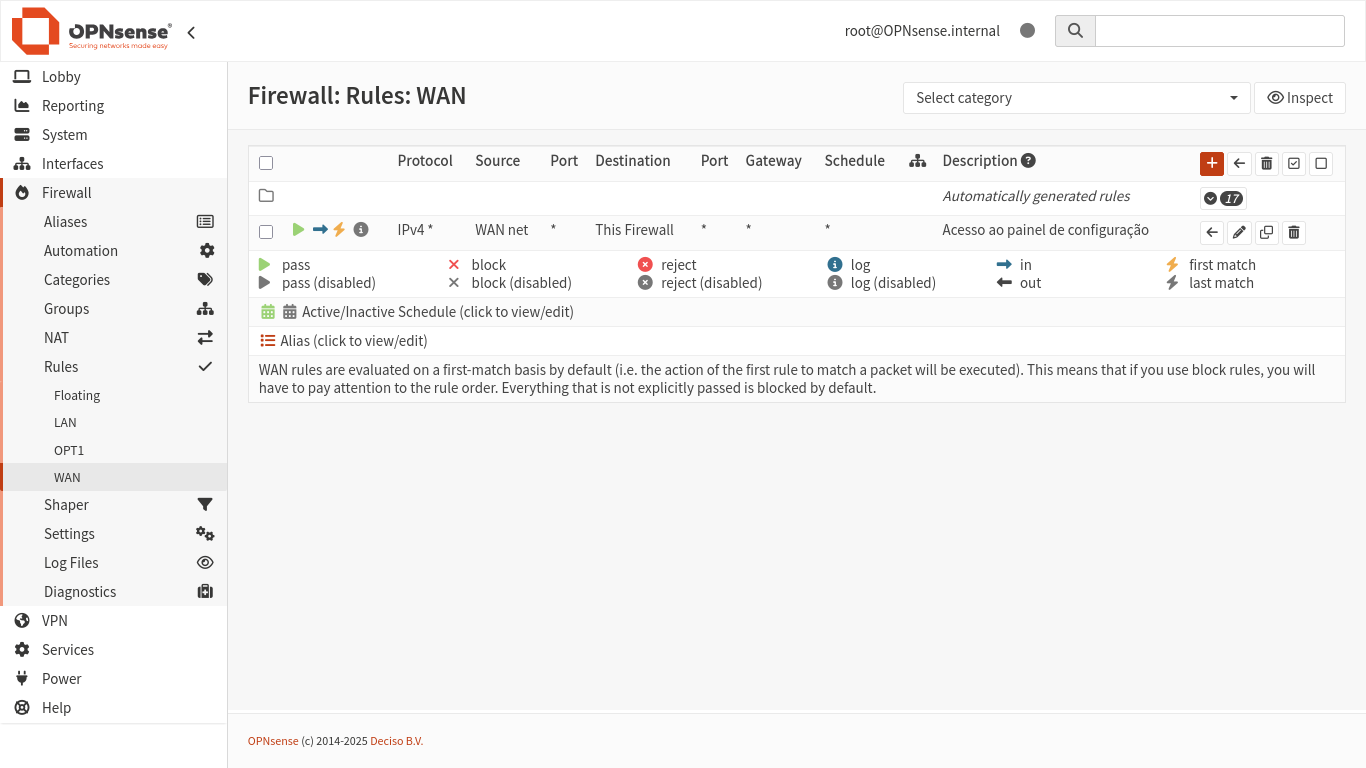
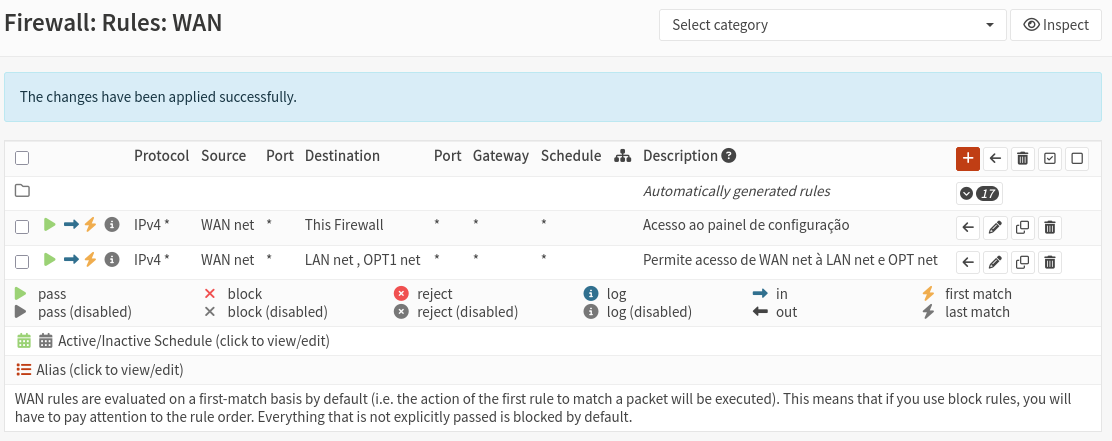
Em Firewall > Rules, crie uma regra para a interface WAN permitindo tráfego de entrada de “WAN net” para o OPNsense.
Agora, você deve alterar no Proxmox a configuração da interface de rede das máquinas virtuais que desejar para que elas utilizem a bridge correspondente à interface LAN do OPNsense.
Você vai ver que, ao pingar um IP da sua LAN física a partir de uma máquina virtual conectada ao OPNsense, a máquina virtual vai receber a resposta. Agora, basta criar a regra que vai isolar a rede LAN do OPNsense da sua LAN física.
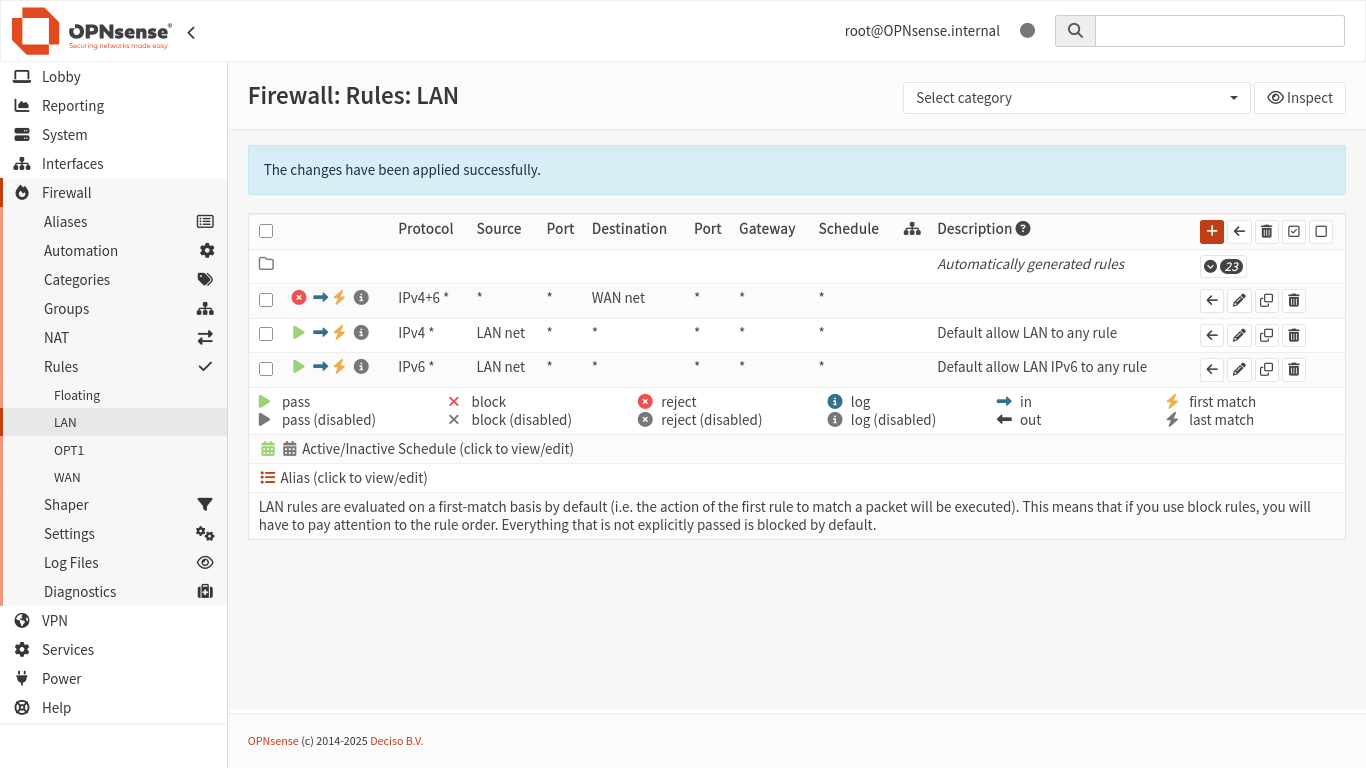
No OPNsense, crie uma regra para a LAN, bloqueando todo tráfego de entrada na interface LAN com destino a “WAN net” e coloque essa regra ao topo das regras padrão de permissão de entrada de tráfego na interface LAN.
Pelo fato de OPNsense ser um firewall do tipo stateful, para garantir que nenhuma conexão já estabelecida se mantenha, vá em Firewall > Diagnostics > States e, na aba Actions, resete a tabela de estado.
Agora, toda máquina virtual que for configurada no Proxmox e precise ficar isolada da rede LAN física, deve ser conectada à bridge correspondente à LAN do OPNsense – nesse caso, vmbr1.
Recomendação de segurança: no OPNsense, crie um usuário, inclua ao grupo admin e, após logar nele, desabilite o usuário root.
Posteriormente, eu vi que existem algumas opções de serviço DHCP. O padrão configurado na linha de comando é o “Dnsmasq DNS & DHCP” e é o mais leve mas parecia não ter a opção de reservas DHCP, então configurei o Kea DHCP, uma implementação mais recente desenvolvida pela Internet Systems Consortium (ISC), para ser usado com as interfaces LAN e OPT1.
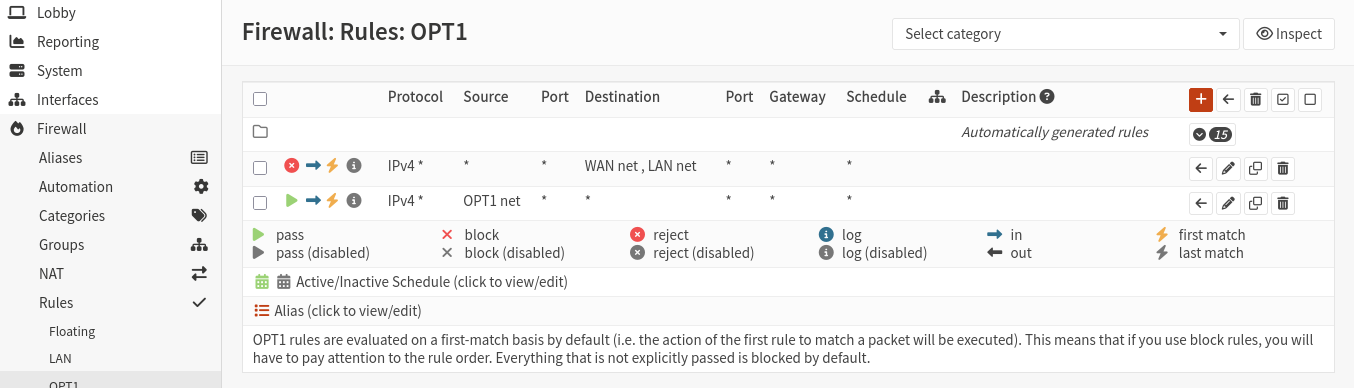
A interface OPT1 foi configurada de forma parecida à LAN mas um pouco mais restrita, com acesso bloqueado tanto à “WAN net” quanto à “LAN net”. A ideia sendo que a LAN vai abrigar os servidores em uso, já relativamente bem configurados e mantidos, enquanto a rede na interface OPT1 vai abrigar máquinas virtuais de teste.
Outra configuração feita posteriormente: foi criada uma regra no firewall para permitir o acesso da rede WAN às redes LAN e OPT1.
Adicionalmente, no roteador da rede física, foi configurada uma rota para as redes LAN e OPT1 através do IP do firewall na WAN.
Dessa forma, conseguimos acessar da rede física as máquinas virtuais nas redes LAN e OPT1 através do IP individual delas, sem necessidade de configuração de encaminhamento de portas para cada uma, enquanto mantendo bloqueado o acesso das redes LAN e OPT1 à WAN.
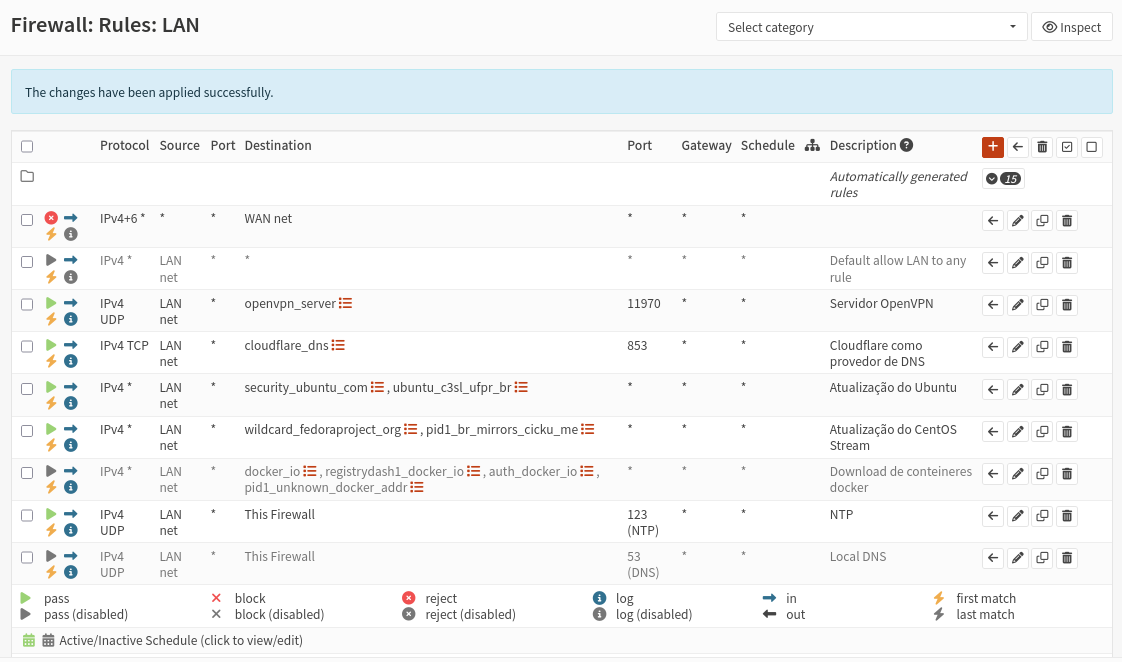
Para a interface LAN, foi restringido o acesso à internet, criando grupos de IPs com alias e liberando o acesso a endereços essenciais, como repositórios de pacotes do Ubuntu e CentOS Stream para manter os sistemas atualizados, servidor de VPN para manter o acesso aos serviços web pelo proxy reverso, e acesso à Cloudflare para DNS sobre TLS, de modo a melhorar a segurança sem quebrar nenhum acesso previamente utilizado.
Esse foi um pouco diferente, mas para dar um contexto de como eu cheguei aqui: além da minha instância Nextcloud, eu mantenho outra para o meu pai, com um HD dele. Meu pai também é da área de Tecnologia da Informação mas com uma vivência muito mais forte em ambiente Windows.
Então eu fiquei me perguntando se não havia alguma alternativa ao Nextcloud que pudesse hospedar no Windows, preferencialmente usando o IIS.
Infelizmente, não consegui nada para IIS, mas consegui algo para Windows: Pydio Cells é uma plataforma de código aberto para hospedagem e compartilhamento de arquivos, com foco em colaboração.
Pydio Cells tem uma configuração relativamente simples, não sendo necessário configurar servidor web ou interpretador PHP, só um banco de dados MySQL ou MariaDB. Por baixo dos panos, o a plataforma é escrita em Go e utiliza o servidor web Caddy. É também compatível com Linux mas dessa vez vamos abordar a configuração em Windows.
O Pydio Cells pode ser encontrado para download aqui e o MariaDB aqui.
Comece instalando o MariaDB. Basta seguir o wizard de instalação com as opções recomendadas. Ele vai instalar junto um programa chamado HeidiSQL, um cliente SQL. Abra-o e conecte no seu banco de dados com o root e a senha definida durante a instalação.
Crie um usuário para o Pydio Cells, um banco de dados e dê todos os privilégios sobre o banco de dados a esse usuário:
CREATE USER 'pydio_admin'@'localhost' IDENTIFIED BY 'senha123';
CREATE DATABASE pydio_db CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
GRANT ALL PRIVILEGES ON pydio_db.* TO 'pydio_admin'@'localhost';
FLUSH PRIVILEGES;
Feito isso, crie uma pasta para a execução e os arquivos de configuração do Pydio Cells:
C:\Users\daniel> mkdir C:\pydio_cells
Extraia o executável do Pydio Cells da pasta zipada e copie-o para esse diretório.
Crie a seguinte variável para o Windows e reinicie o sistema operacional para que a alteração tenha efeito:
O instalador irá perguntar pelo modo de instalação. Você pode selecionar pelo navegador web e seguir por lá. Conecte no seu banco de dados com o usuário e a senha que você criou no HeidiSQL e crie o seu usuário para login no Pydio Cells. Você pode acompanhar o progresso pelo terminal. Ao fim da instalação, a página de login deverá aparecer.
Você vai ver que ele abre por padrão na porta 8080 com HTTPS, lembre-se de abrir essa porta no firewall do Windows para acesso através de outros clientes:
Você já deve conseguir acessar o servidor através de outros dispositivos na sua rede.
Para integrar à minha infraestrutura existente, esse servidor também foi colocado atrás do proxy reverso, e a configuração de diferentes proxys, incluindo o nginx, são abordadas na própria documentação do Pydio Cells.
Use o seguinte comando para determinar o endereço onde ele escuta por conexões e o endereço externo utilizado para o proxy reverso:
C:\pydio_cells\cells.exe configure sites
Nesse caso, foi configurado como:
BIND: https://0.0.0.0:8080
TLS: auto-assinado
URL externa: https://pydio.exemplo.com
Note que uma porta diferente pode ser utilizada para a URL externa. Caso pretenda configurar a integração com o Collabora, como foi feito para o Nextcloud, mantenha o acesso na URL externa pela porta padrão, visto que o Collabora retorna erro 403 quando usado com portas alternativas.
O domínio do Collabora também deve ser o mesmo que o do Pydio Cells, como collabora.exemplo.com e pydio.exemplo.com, resultando também em erro 403 quando configurado com domínios diferentes.
Agora, o Pydio Cells não se inicia automaticamente junto com o Windows, precisando ser iniciado manualmente com:
C:\Users\daniel> C:\pydio_cells\cells.exe start
Você pode no entanto configurar o Pydio Cells para ser executado como um serviço do Windows, iniciando junto com o sistema operacional.
O Windows tem 3 usuários para serviços: Local System, Network Service e Local Service, do maior ao menor nível de acesso ao sistema. Para utilizar Local Service, precisamos dar permissão de acesso à pasta do Pydio Cells e suas subpastas.
Uma desvantagem (para mim) que eu encontrei no Pydio Cells em relação ao Nextcloud é que, ao fazer upload de arquivos, eles são armazenados no Windows sob um nome diferente, utilizando UUIDs, e sem estrutura de pastas separando os arquivos por usuários ou replicando a estrutura de pastas existente dentro da plataforma, armazenando informações referentes à organização de pastas e arquivos apenas no banco de dados.
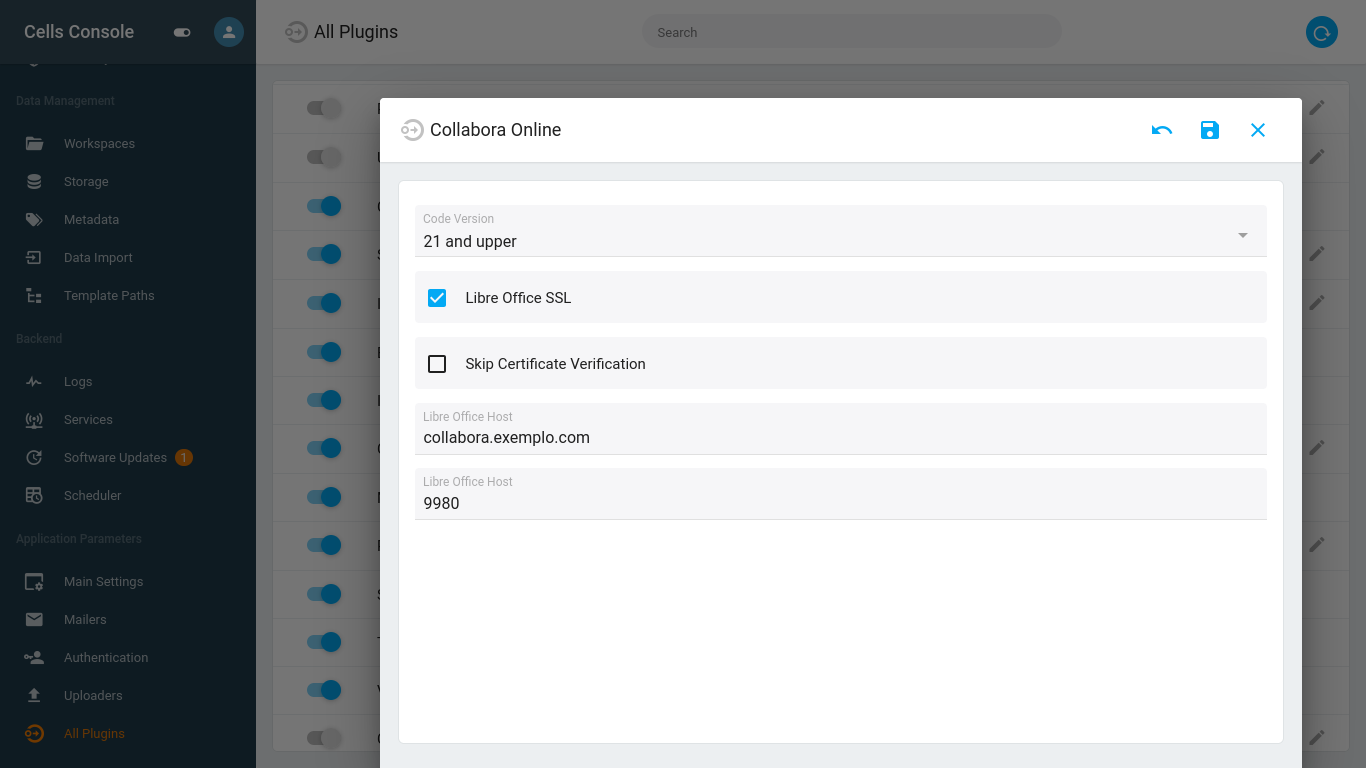
A integração com um servidor Collabora existente é feita através do Cells Console. Ative a chave no topo da página para mostrar as configurações avançadas e, no fim da lista aparece a área “All Plugins”, onde a conexão com o Collabora é configurada e o plugin do Collabora deve ser ativado.
Nextcloud tem um ecossistema com muitas possibilidades de aplicativos e funcionalidades adicionais que podem ser integradas. Uma das integrações mais comuns de serem feitas é com uma suíte office, permitindo edição e colaboração em documentos, planilhas e apresentações, como também é feito através do Google Workspace.
Essa integração é feita conectando o Nextcloud a uma plataforma de colaboração e edição de documentos acessível via web. Existem duas principais plataformas como opções: ONLYOFFICE Docs Community e Collabora Online Developer Edition (CODE).
Ambos têm uma UI familiar para usuários do Microsoft Office, ambos são compatíveis com o padrão Open Document Format (ODF), que engloba os formatos de arquivos .ods e .odt, e também com o Office Open XML (OOXML) da Microsoft, que engloba os formatos .xlsx e .docx.
Enquanto o ONLYOFFICE é um projeto independente, o Collabora é um projeto baseado no LibreOffice, mas construído com uma UI diferente. Ambos também são distribuídos em formato Docker, o que permite uma facilidade de instalação e instruções independem do sistema operacional anfitrião.
Eu já usei tanto o LibreOffice quanto o ONLYOFFICE Desktop Editors, versões offline das suítes e, enquanto um grande ponto forte do ONLYOFFICE é a compatibilidade com o padrão OOXML criado pela Microsoft, acabei aderindo ao LibreOffice por questão de desempenho.
Como já me deparei com pequenas inconsistências de formatação ao criar um documento em uma suíte e abrir em outra, seguir com o Collabora foi mais adequado para manter uma boa compatibilidade com meus documentos existentes.
A instalação foi feita com Docker através da minha instalação do Portainer. Ao criar um contêiner, defina o nome, a imagem a ser usada para a implantação e o mapeamento de portas.
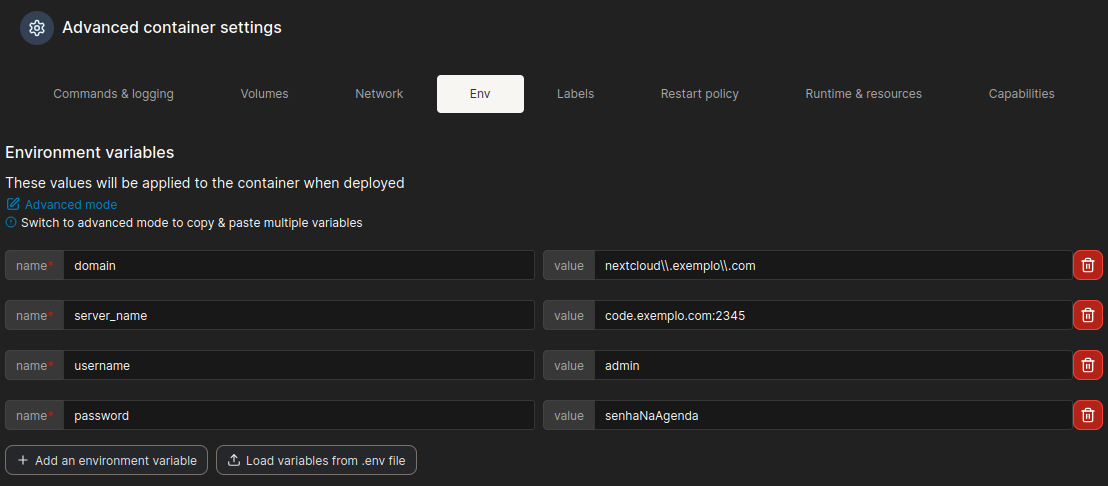
Nas configurações avançadas, defina as variáveis de ambiente:
domain – endereço do Nextcloud que irá utilizar a plataforma CODE, expresso como regex.
server_name – nome do servidor que hospeda o CODE e a porta exposta. A porta pode ser diferente da 9980 mapeada pelo docker, dependendo da regra de encaminhamento de porta no firewall OU do proxy reverso utilizado.
username e password – usuário e senha para o painel de administrador.
Observações:
O servidor precisa ter o mesmo domínio que o Nextcloud – nesse caso exemplo.com, caso contrário o Collabora retorna erros 403.
Além disso, o Nextcloud precisa estar exposto na porta padrão HTTPS. Quando exposto em portas alternativas, essa porta é passada para o servidor CODE como parte da URL na requisição HTTP e o Collabora não identifica, recusando a conexão com código 403.
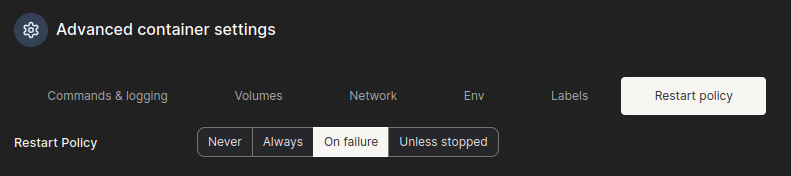
Defina a política de reinicialização.
E então, basta implantar o contêiner. Alternativamente, utilizando o Docker por linha de comando em vez do Portainer:
A configuração do proxy reverso, além de necessária para minha infraestrutura, é recomendada e a configuração para o nginx é fornecida no próprio site do projeto. Adaptando para esse caso:
Web Application Firewall é um tipo de aplicação que inspeciona as requisições HTTP em busca de ameaças comuns, como injeções de SQL, cross-site scripting (XSS), tentativas de inclusão de arquivos remotos e injeção de comandos, antes de encaminhá-las ao servidor web.
São tipos de ameaças que costumam ser tratadas no back-end dos sites, mas nem sempre acontece. Eventualmente desenvolvedores esquecem de sanitizar um input em alguma parte do código e vulnerabilidades surgem. Um exemplo disso é a vulnerabilidade por injeção de SQL no Zabbix que foi encontrada no final de 2024.
Tendo isso em vista, é interessante ter uma camada extra de segurança que verifique cada requisição HTTP. É aí que entra o Web Application Firewall (WAF): ele atua como um proxy reverso + firewall. Recebe a requisição HTTP, inspeciona e, caso ela infrinja alguma regra, impede a conexão. Caso contrário, encaminha a requisição para o servidor web.
Existem diferentes alternativas de WAF, incluindo serviços em nuvem como o Azure Web Application Firewall. Mas minha infraestrutura já utilizava o nginx como proxy reverso para os meus servidores web, então busquei uma alternativa que fosse gratuita e que usasse poucos recursos de hardware, de forma que coubesse no meu VPS de 1 vCPU e 512 MB de RAM.
A que melhor se encaixou foi o ModSecurity, um módulo de código aberto originalmente escrito para trabalhar com o Apache, mas que hoje também funciona com o nginx. Para instalar no meu servidor, que roda Debian 12:
O pacote modsecurity-crs é o Core Rule Set da OWASP, um conjunto de regras base utilizado pelo ModSecurity para identificar e bloquear potenciais ameaças.
Verifique que o módulo está habilitado. Na pasta /etc/nginx/modules-enabled deve haver um softlink como
Em seguida, edite o arquivo de configuração /etc/nginx/modsecurity.conf e configure o seguinte parâmetro:
SecRuleEngine On
Edite também o arquivo /etc/nginx/modsecurity_includes.conf, copiando para ele as linhas em /usr/share/modsecurity-crs/owasp-crs.load que começam com “Include”. Essas são o conjunto base de regras da OWASP.
Seu arquivo deve ficar algo como:
include modsecurity.conf
#include /usr/share/modsecurity-crs/owasp-crs.load
Include /etc/modsecurity/crs/crs-setup.conf
Include /usr/share/modsecurity-crs/rules/*.conf
Feito isso, você pode editar os arquivos de configuração dos sites existente para adicionar no topo no bloco server as seguintes linhas:
Você também pode colocar um input como “UNION SELECT” em algum campo do seu site e verificar que ele responde com 403.
Agora, problemas como falsos positivos podem acontecer. Eu fiquei impossibilitado de publicar ou salvar publicações como rascunho aqui no WordPress, por exemplo, recebendo o erro “Falha ao atualizar. A resposta não é um JSON válido”.
Para resolver isso, foi necessário coletar as informações do log para criar uma regra que permita esse caso e ignore a regra que causa o bloqueio.
id:10001 – ID da regra que você está criando. Deve ser único.
phase:1 – indica que a ação deve ocorrer na fase dos cabeçalhos de requisição – quando o ModSecurity recebe o cabeçalho do nginx, antes de receber o corpo da requisição HTTP e aplicar as regras, que seria a phase:2
nolog – sem necessidade de registrar esse evento
pass – permite a requisição HTTP
ctl:ruleRemoveById=941180 – desabilita a regra que causava o bloqueio. Múltiplas ações desse tipo podem ser especificadas na mesma regra.
Há também no log uma regra de ID 949110, mas ao ver a mensagem associada é possível verificar que ela não é a regra que identifica a ameaça em potencial, apenas a regra que determina um limite de ameaças detectadas. Não desabilite essa regra, isso abriria espaço para outras requisições HTTP que não devem ser recebidas pelo servidor. É preciso analisar o log com atenção e verificar a que mensagens cada regra está associada.
Esse tipo de ajuste também pode ser feito para outras regras em outras URIs de outros sites para os quais o nginx atua como proxy reverso, permitindo o uso do WAF para diferentes aplicações e sistemas.
Uma observação importante: a ordem em que as configurações são incluídas no arquivo /etc/nginx/modsecurity_includes.conf é importante, já que as regras são processadas de forma sequencial. Garanta que as exceções são incluídas para serem processadas antes das regras da OWASP.
Include modsecurity.conf
Include modsecurity_custom_exceptions.conf
Include /etc/modsecurity/crs/crs-setup.conf
Include /usr/share/modsecurity-crs/rules/*.conf
Para casos em que uploads de arquivos são feitos, como no Nextcloud, considere também ajustar no arquivo /etc/nginx/modsecurity.conf o parâmetro de tamanho máximo do corpo das requisições HTTP, especificado em bytes.
O limite padrão é 12.5 MB, tendo sido ajustado para 30 MB. Idealmente ajustaria para um valor mais alto mas o consumo de memória pelo nginx ultrapassa o limite tolerado pelo systemd-oomd no meu servidor com 512 MB de RAM, levando o systemd-oomd a matar o processo.
Network File System (NFS) é um protocolo de sistema de arquivos sobre rede e permite compartilhamento de pastas e arquivos entre computadores.
Ele é consideravelmente mais simples que o Server Message Block (SMB), protocolo usado pelo Windows para compartilhamento de pastas e impressoras, de forma que não possui qualquer suporte a autenticação de usuário ou criptografia. O controle de acesso é feito por endereço IP e pelas permissões do próprio sistema de arquivos.
Ele tem como objetivo ser simples e transparente para aplicações de forma que pareça fazer parte do sistema de arquivos no cliente, enquanto mantém um bom desempenho.
Esse protocolo existe nativamente em sistemas tipo Unix, como Linux, macOS e FreeBSD. No Windows, o suporte ao protocolo precisa ser adicionado como um pacote extra, mas é oferecida pela própria Microsoft.
Em servidores Debian, Ubuntu ou derivados, instale o servidor NFS com:
# apt install nfs-kernel-server
Crie a pasta a ser exportada e defina as permissões adequadas – Proxmox vai escrever como root no sistema de arquivos exportado:
O servidor NFS usa a opção root_squash por padrão na configuração, que mapeia as escritas do root do cliente para a uid e gid de um usuário de privilégio mais baixo no sistema. Escrita e leitura de outros usuários não são afetadas e levam a mesma uid e gid que o usuário do cliente.
Edite o arquivo /etc/exports para adicionar a pasta a ser exportada, o IP do cliente que vai acessá-la e os parâmetros de configuração da exportação:
/pmx-backup 192.168.0.2(rw,sync,no_subtree_check)
E então exporte os sistemas de arquivos configurados:
# exportfs -ar
Abra a porta para o NFSv4 (essa versão requer apenas a porta 2049/tcp):
# ufw allow proto tcp from 192.168.0.2 to any port 2049
Onde 192.168.0.2 é o IP do servidor Proxmox.
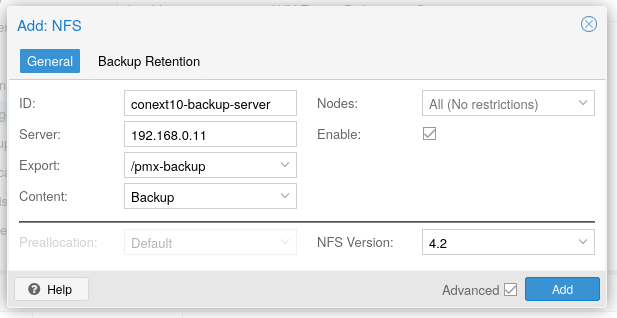
Para configurar o armazenamento no Proxmox, vá em Datacenter > Storage > Add > NFS e preencha com as informações necessárias:
Sendo uma alternativa ao ambiente Microsoft, o Google Workspace também conta com um serviço de diretório. O LDAP seguro pode ser usado para autorização e autenticação de usuários. O FreeRADIUS foi usado para implementar autenticação WPA2-Enterprise na rede Wi-Fi, com um detalhe: a autenticação precisava funcionar para 2 domínios de e-mail diferentes, de dois ambientes Google Workspace independentes.
Enquanto a autenticação com AD no FreeRADIUS é feita através do método de desafio e resposta, MSCHAPv2, o LDAP seguro do Google não implementa esse protocolo e precisa que a senha do usuário seja enviada em texto pleno dentro de um túnel SSL. Isso pode ser feito com a combinação de protocolos EAP-TTLS/PAP. Diferente do EAP-TLS, que exige o par de certificado/chave tanto do cliente quanto do servidor, o EAP-TTLS exige o par apenas do servidor.
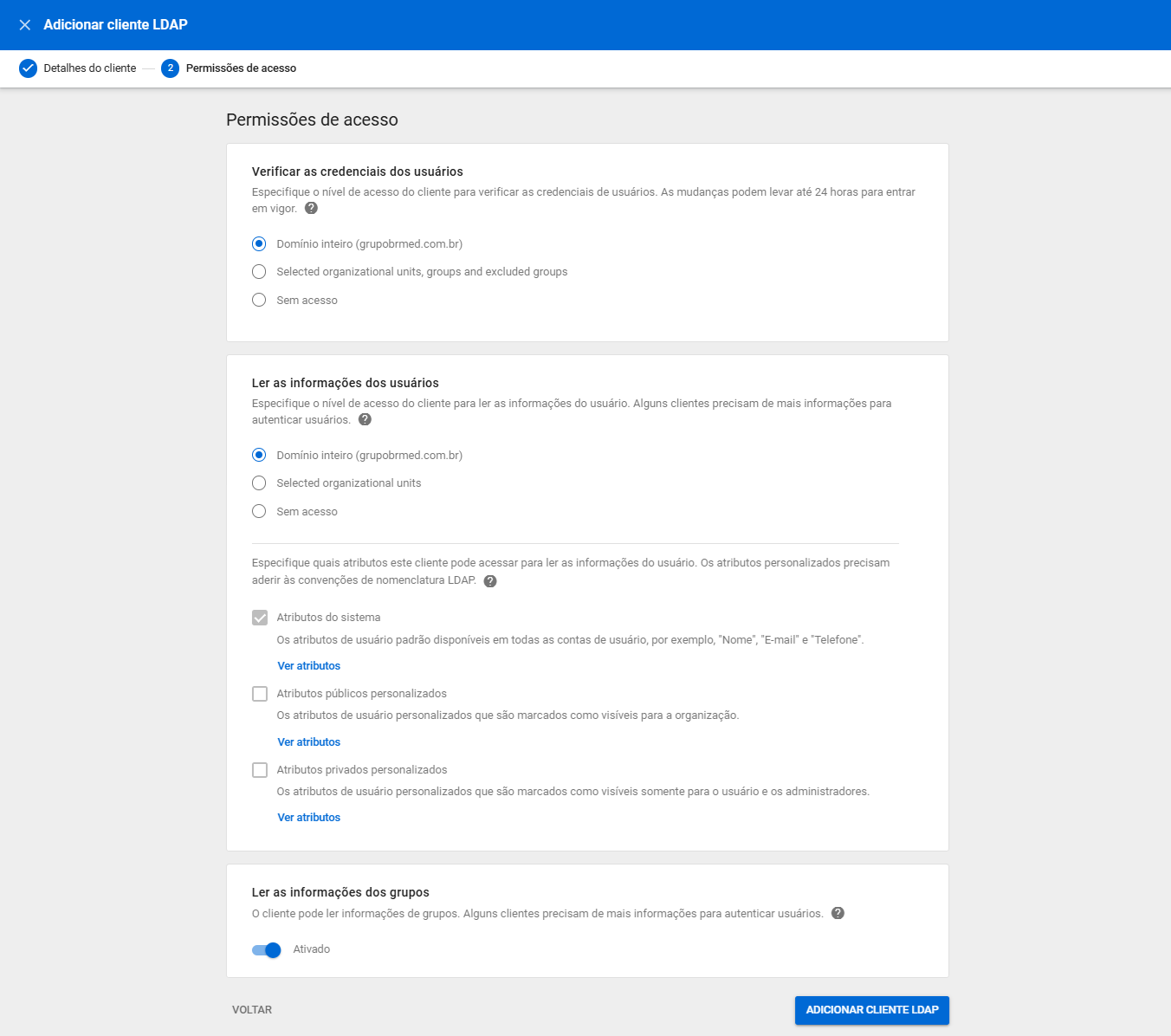
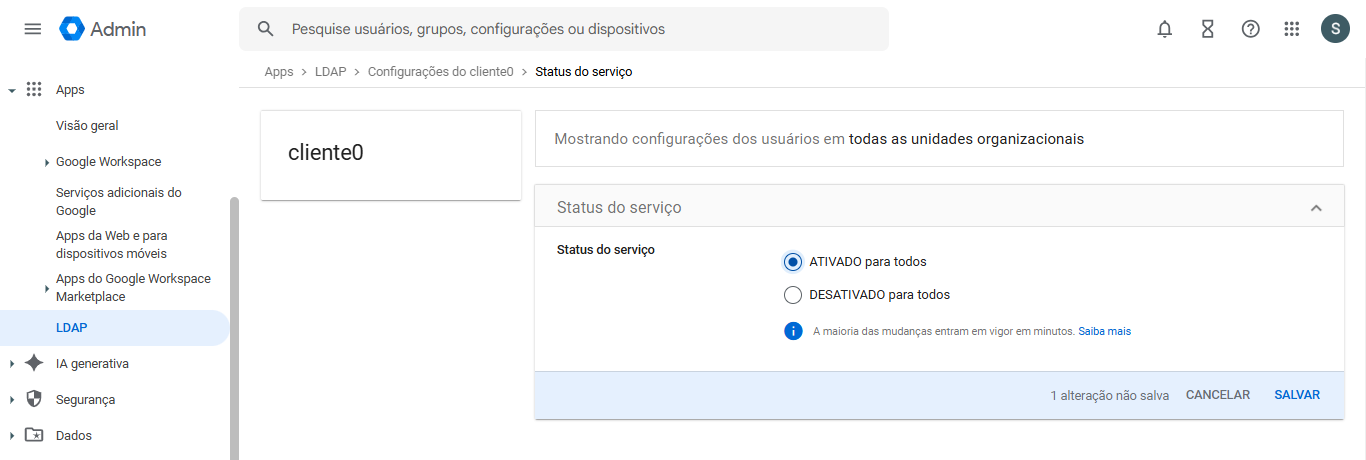
O servidor utilizado foi o Ubuntu 24.04 mas o processo serve também para outras versões. Primeiro passo é criar o cliente LDAP no Google Workspace. No console de administrador, vá em Apps > LDAP > Adicionar Cliente
Atribua as permissões necessárias para o cliente:
Em seguida, baixe os certificados e ative o serviço.
Agora, preparando o servidor FreeRADIUS:
# apt install freeradius freeradius-ldap
Diferente do CentOS, o Ubuntu já gera os certificados pro TLS automaticamente no processo de instalação.
Diferentes clientes podem ser adicionados no arquivo /etc/freeradius/3.0/clients.conf em blocos do tipo:
Transfira o par de certificado/chave baixado do Google Workspace para o servidor, armazenando-os em /etc/freeradius/3.0/certs/google/, onde já é esperado pelo FreeRADIUS nas configurações a se seguir.
Partindo para os arquivos de configuração, a começar pelo LDAP, fazendo uma cópia do arquivo para cada ambiente Workspace:
# cp -a /etc/freeradius/3.0/mods-available/{ldap_google,ldap_workspace0}
# cp -a /etc/freeradius/3.0/mods-available/{ldap_google,ldap_workspace1}
Edite o arquivo, adicionando ou alterando as linhas:
Caso tenha alterado os certificados a serem usados, você também vai precisar editar as configurações referentes a isso no bloco de configurações comuns de TLS.
Você pode comentar outros módulos não utilizados, como TLS, PEAP e MSCHAPv2, deixando apenas as configurações comuns de TLS e o bloco do TTLS.
O arquivo /etc/freeradius/3.0/sites-enabled/default tem diversas opções, muitas podem (e devem) ser desabilitadas. Edite os blocos authorize e authenticate para que fiquem como abaixo:
No arquivo /etc/freeradius/3.0/sites-enabled/inner-tunnel, edite os mesmos blocos, adicionando a condicional para os dois domínios:
server inner-tunnel {
authorize {
filter_username
if ("%{User-Name}" =~ /@dominio0\.com$/) {
ldap_workspace0
update control {
Auth-Type := ldap_workspace0
}
} elsif ("%{User-Name}" =~ /@dominio1\.com$/) {
ldap_workspace1
update control {
Auth-Type := ldap_workspace1
}
} else {
reject
}
expiration
logintime
}
authenticate {
Auth-Type ldap_workspace0 {
ldap_workspace0
}
Auth-Type ldap_workspace1 {
ldap_workspace1
}
Auth-Type PAP {
pap
}
}
}
Terminando a edição dos arquivos, você deve reiniciar o serviço para que as configurações tenham efeito, garantindo antes que todos os arquivos pertencem ao usuário e grupo freerad.
Nesse caso, a melhor abordagem foi usar a condicional considerando o cliente do RADIUS e o ambiente Workspace porque os dois ambientes podem ter UOs diferentes e VLANs com IDs diferentes.
Como se pode ver pelo sinal =~ a checagem da UO não é exata e o mesmo nome poderia ser encontrado em outra UO, o que pode fazer com que a VLAN errada seja atribuída a um usuário.
Uma forma mais adequada de atribuir uma VLAN seria, ao invés de usar as unidades organizacionais do Workspace para determinar a VLAN diretamente, usar as unidades organizacionais para atribuir usuários a grupos dinâmicos como rh-wifi@dominio0.com que então vão ser verificados pelo FreeRADIUS da seguinte forma:
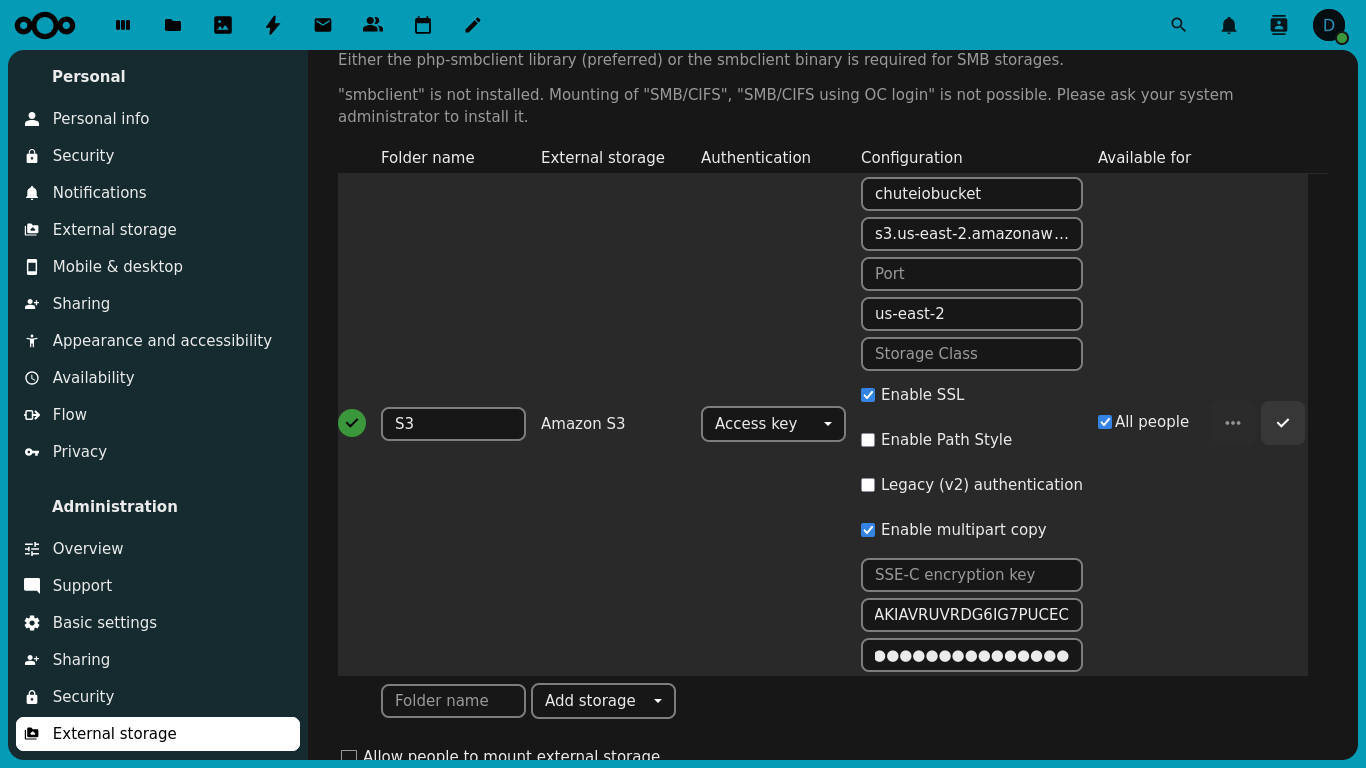
Nextcloud tem suporte a diferentes tipos de armazenamentos externos através do app “External storage support”, entre eles: SMB (compartilhamento de pasta do Windows), SFTP e Amazon S3.
Amazon Simple Storage Service (S3) é um serviço de armazenamento de objetos, que se diferencia do armazenamento de arquivos em alguns aspectos. Um deles sendo que, enquanto que em armazenamento de arquivos existe uma hierarquia de pastas ou diretórios, no armazenamento de objetos eles se encontram todos no mesmo ambiente, chamado bucket.
Aplicações conseguem, no entanto, simular essa estrutura de pastas, graças ao fato de que o caractere / é permitido no nome dos objetos. E é exatamente isso que acontece no Nextcloud e no utilitário de linha de comando aws.
A forma como o armazenamento de objetos é construído permite uma alta escalabilidade e, diferente de um serviço de armazenamento de arquivos como Google Drive, em que você contrata uma quantidade de armazenamento para ter disponível, nos serviços de armazenamento de objetos você paga pelo que é usado.
Esse tipo de serviço é comumente usado em cenários de armazenamento de grande escala, como backups, CDNs, dados para treinamento de LLMs como ChatGPT e Gemini, onde não há necessidade de edição de arquivos no armazenamento.
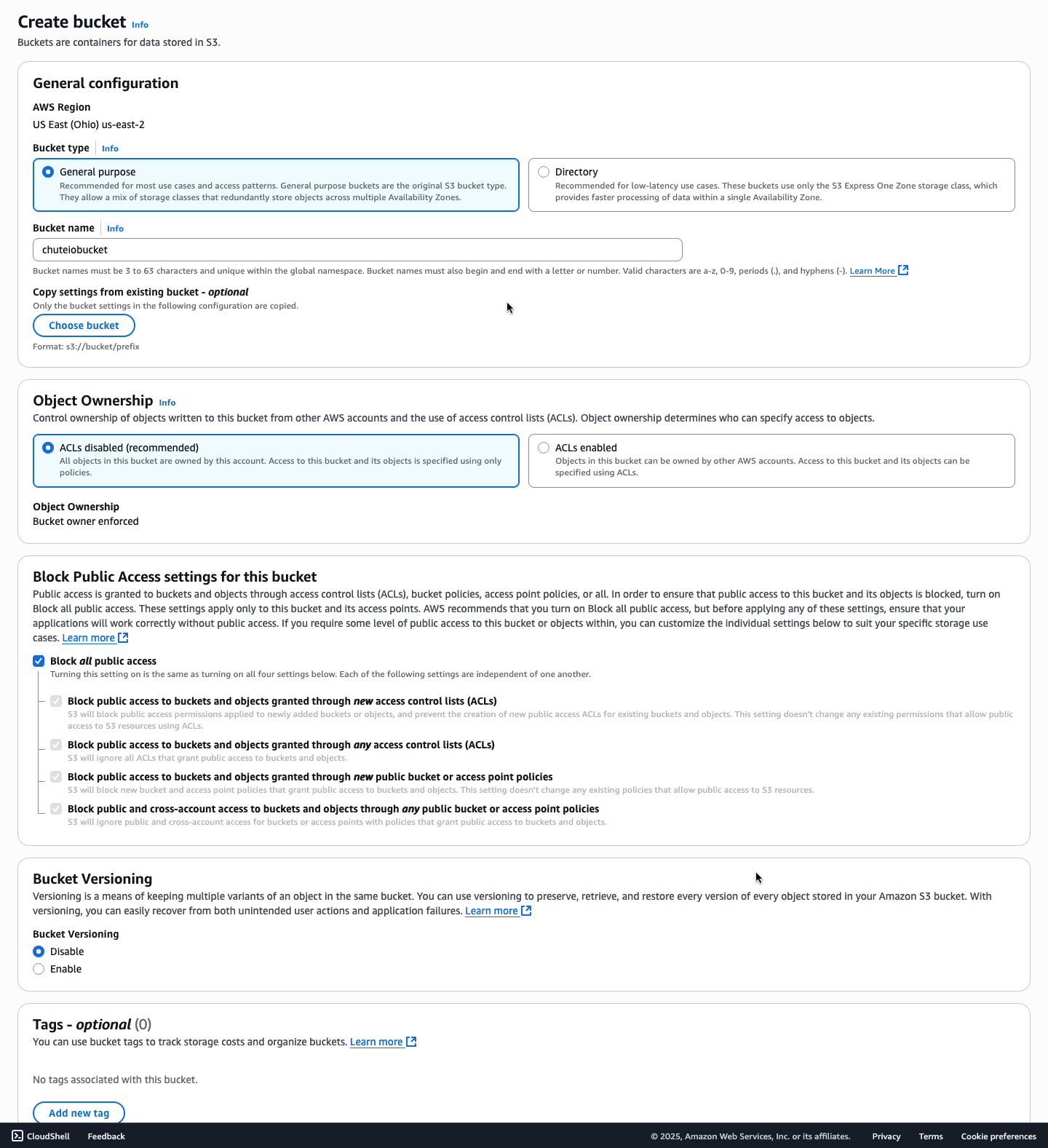
Partindo para a prática, o bucket foi criado de forma simples, mantendo as opções padrões:
Agora deve-se criar um usuário, um grupo, adicionar o usuário ao grupo e criar uma política para dar acesso ao bucket para o usuário. Isso pode ser feito através do console:
Você pode permitir acesso do grupo ao bucket através da política de permissão existente AmazonS3FullAccess. Isso daria acesso a todos os buckets existentes na conta para esse grupo. Isso pode não ser desejável. Uma alternativa é criar uma política de permissão, que pode ser feita no formato json:
Verificado o funcionamento, basta configurar no Nextcloud: habilite o aplicativo “External storage support” e ajuste as configurações de acordo com as preferências.
O host foi um pouco difícil de descobrir, não encontrei na AWS de forma tão explícita. Em vez disso, ao selecionar um objeto existente no bucket (que fiz upload com o utilitário de linha de comando), aparecia a opção de copiar URL, e foi como vi que o endereço era: s3.<região da AWS>.amazonaws.com
Ao conectar, o armazenamento S3 aparece como uma pasta para os usuários que você determinar. Adicionalmente, é possível permitir que usuários adicionem armazenamentos externos, como o S3, para as próprias contas.
Um dia o nginx que configurei como proxy reverso aqui passou a dar timeout ao tentar carregar o Nextcloud. Ao investigar, verifiquei que mesmo ao fazer a solicitação ao servidor Nextcloud a partir do próprio servidor que hospeda o nginx/OpenVPN, através do comando abaixo, a solicitação não completava.
$ curl -v http://10.8.0.3
As solicitações feitas dentro da LAN funcionavam, indicando que o problema acontecia apenas dentro da VPN. No entanto, dentro da VPN o ping funcionava, solicitações para outras páginas do Nextcloud também funcionavam, como:
$ curl -v http://10.8.0.3/status.php
Tentei aprofundar a investigação mas eu não sou nenhum especialista em redes, só um entusiasta que se mete profissionalmente. Uma explicação que consegui foi que o problema podia ser relacionado ao MTU (maximum transmission unit) da interface virtual de rede do OpenVPN.
Tanto a interface virtual do OpenVPN (tun0) quanto a interface de rede da máquina (eth0) possuíam o mesmo MTU: 1500 bytes. Isso pode ser verificado com:
$ ip a
Diminui o MTU do tun0 para 1380, tanto no servidor quanto no cliente, que foi uma sugestão que encontrei e funcionou. Esqueci o problema até acontecer com outra instalação do Nextcloud que mantenho. Mesmo problema, mesma solução. Eventualmente retornei o MTU pra 1500 e continuou funcionando.
O blog não existia na época da primeira ocorrência com o Nextcloud. Agora, tive o mesmo problema com o WordPress e o novo Nextcloud. E o problema parece inconsistente. Tudo funciona, até que de repende para. E em momentos diferentes, sem nenhum gatilho claro, mas claramente alguma tentativa de enviar um pacote maior que não poderia ser fragmentado falhou.
Dessa vez parei pra investigar um pouco melhor. Já que o MTU da tun0 é 1500, um ping com tamanho de 1472 bytes (-20 do cabeçalho IP -8 do cabeçalho ICMP) deve passar sem ser fragmentado. Não passou. 100% dos pacotes perdidos. Fui baixando até encontrar o ponto onde os pings tem resposta: 1396 bytes. MTU de 1424 bytes.
Testei então: ping sem opções definidas e com tamanhos 1396 e 1397 bytes, monitorando também com o tcpdump tanto no servidor quanto no cliente:
$ ping 10.8.0.3
$ ping -M do -s 1396 10.8.0.3
$ ping -M do -s 1397 10.8.0.3
Para o tcpdump:
# tcpdump -i tun0 icmp
Resultados:
“ping 10.8.0.3” e “ping -M do -s 1396 10.8.0.3”:
pra cada 10 pings, 0% de perda de pacotes.
tcpdump reporta 20 pacotes capturados tanto no servidor quanto no cliente: solicitação e resposta
Ótimo. Agora:
“ping -M do -s 1397 10.8.0.3” e valores acima:
pra cada 10 pings, 100% de perda de pacotes
tcpdump reporta 10 pacotes capturados no servidor, 20 no cliente: o pacote sai do servidor e chega ao cliente, que responde, mas as respostas do cliente não chegam ao servidor.
O mesmo foi feito pingando do cliente para o servidor. Mesmo sucesso para pacotes de 1396 bytes e menores. Já com
ping -M do -s 1397 10.8.0.1:
pra cada 10 pings, 100% de perda de pacotes
tcpdump reporta 10 pacotes capturados no cliente, 0 no servidor.
Ou seja, o problema está no envio de pacotes dos clientes para o servidor através do túnel.
O ping não alerta que o pacote é grande demais nem dá qualquer erro específico, apenas para pings com tamanho acima de 1472 (que resultariam num pacote acima do MTU). Em vez disso, apenas falha silenciosamente.
Adicionalmente ao ping, fiz testes com requisições às páginas que resultavam em timeout usando curl e monitorando com tcpdump.
Solução: baixar o valor do MTU da interface tun0 do servidor e clientes da VPN para 1424 bytes: tamanho total do maior pacote do ping que funcionou (1396 de payload, 20 do cabeçalho IP e 8 do cabeçalho ICMP).
Isso pode ser feito de forma não persistente com:
# ip link set dev tun0 mtu 1424
O MTU vai voltar para 1500 quando o serviço do OpenVPN for reiniciado. Para configurar de forma persistente, inclua essa linha nos arquivos de configuração do OpenVPN do servidor e dos clientes:
tun-mtu 1424
Eu ainda não entendi 100% o que causa esse problema e ele não parece afetar todos os clientes igualmente ou ao mesmo tempo. O servidor recebia resposta do ping com payload de 1472 de alguns clientes sem problemas, que exibiam a página e operavam com a MTU padrão de 1500 bytes no tun0.
Até então, após a mudança para o MTU de 1424, o problema não reincidiu. Sendo mais conservador, eu colocaria um valor mais baixo, pra deixar uma margem pra possíveis alterações que possam vir a acontecer no OpenVPN ou nos outros servidores, masss eu tô aqui pra ver o que acontece.
Docker é uma ferramenta que permite a distribuição de softwares em contêineres, ambientes de execução independentes. Algo como máquinas virtuais, mas sem o mesmo overhead da virtualização de hardware e sem necessidade de outro kernel sendo executado.
Isso permite que os desenvolvedores tenham um maior controle sobre versões de dependências como bibliotecas e outros programas com que o software interage, independente da distribuição Linux onde o software vai ser executado.
Isso também facilita a implantação, já que muita coisa no ambiente não precisará ser configurada após a instalação.
Portainer é uma ferramenta para gerenciamento e monitoramento de contêineres Docker, podendo também gerenciar Podman e Kubernetes. É distribuído também como um contêiner Docker.
Começando pela instalação do Docker pelas fontes oficiais, nesse caso para o Ubuntu Server 24.04, é necessário primeiro importar a chave do repositório do Docker:
O parâmetro -p é usado para mapear uma porta do host para uma porta do contêiner – docker usa iptables e isso pode contornar o firewall do sistema operacional.
O parâmetro -v é usado para mapear um volume docker ou um /caminho/no/seu/sistema para um caminho dentro do contêiner.
A porta 9443 é usada para acesso à interface web via HTTPS. Por padrão são gerados certificados autoassinados e, enquanto é possível especificar seus certificados já no comando “docker run”, também é possível alterá-los pelas configurações na própria interface web.
A porta 8000 é usada pela funcionalidade Edge computing, que permite gerenciamento e implantação de contêineres em dispositivos remotos através de um túnel TCP.
Verifique que o Portainer está sendo executado com:
$ docker ps
Então, acesse-o pelo navegador através da porta 9443 com protocolo HTTPS e siga a configuração pela página web.
Hora de instalar um contêiner: existem alguns templates mas a seção Containers permite que qualquer imagem seja baixada do Docker Hub e o contêiner construído a partir dela, com os parâmetros de configuração escolhidos.
Um software interessante que é distribuído como um contêiner docker é o Metabase: uma plataforma livre e aberta para análise de dados e Business Intelligence.
De acordo com o site oficial, a instalação como contêiner docker pode ser feita pelo seguinte comando:
$ docker run -d -p 3000:3000 --name metabase metabase/metabase
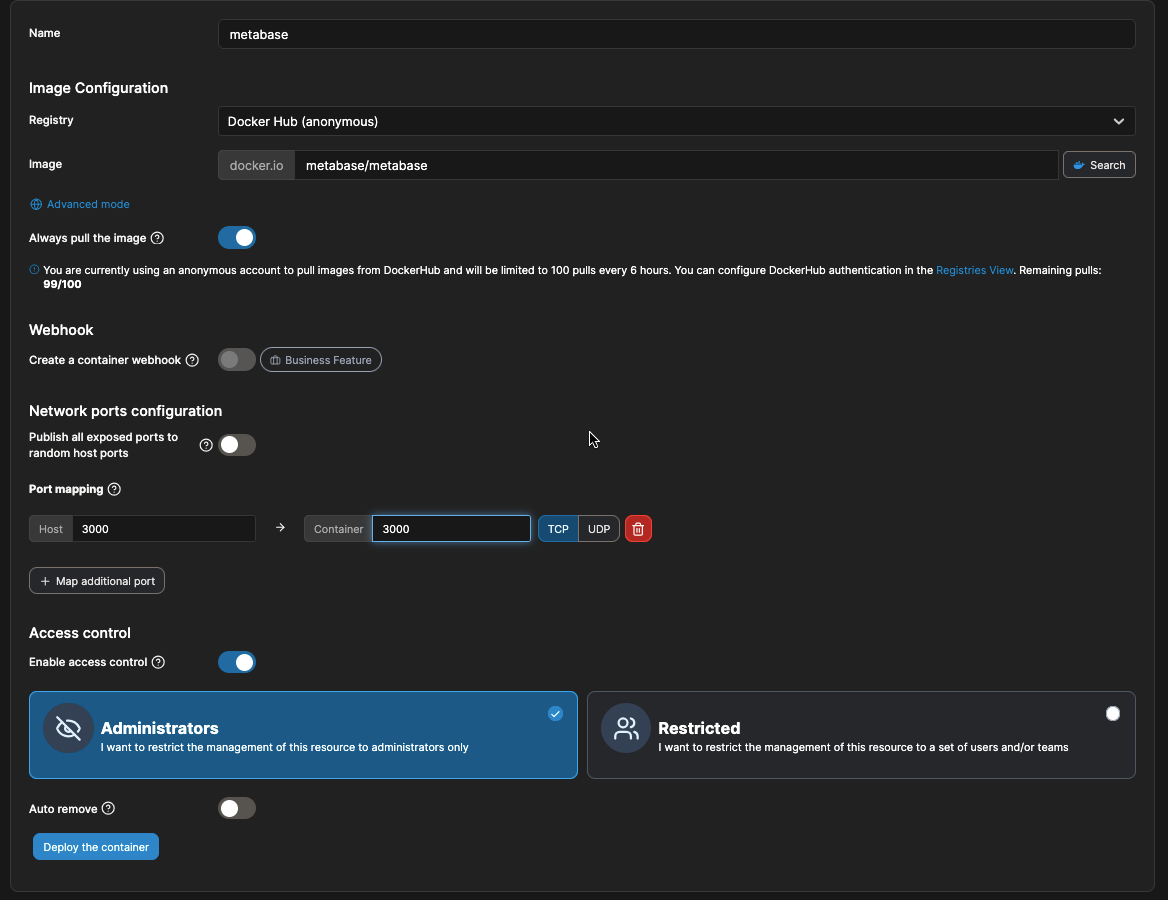
O que, pelo Portainer, fica:
Após inicializado, basta acessar o servidor na porta 3000 via HTTP.
O comando “docker run” é tipicamente usado para softwares ou sistemas que são distribuídos como um único contêiner. Alguns sistemas são compostos de múltiplos contêineres que trabalham em conjunto.
Nesses casos, em vez de usar o comando “docker run” passando os parâmetros de configuração como argumentos, o comando “docker compose” é usado com um arquivo docker-compose.yml que armazena esses parâmetros de configuração. A configuração do Metabase nesse formato, por exemplo, ficaria:
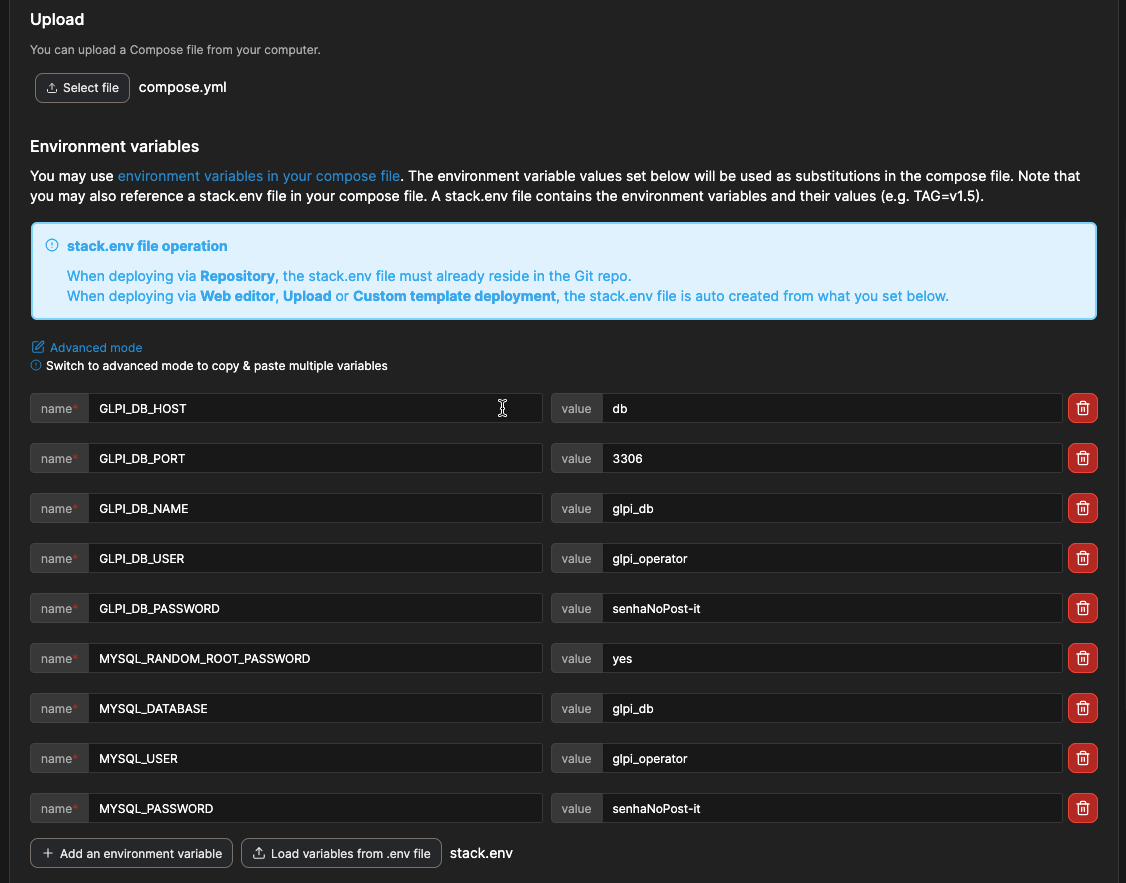
Outro sistema interessante de ser instalado é o GLPI: um sistema de gerenciamento de Helpdesk e ativos de TI. A instalação usa um arquivo docker-compose.yml, que pode ser encontrado no Docker Hub: https://hub.docker.com/r/glpi/glpi, e especifica dois contêineres: um com o GLPI empacotado com o servidor web e PHP e outro com o banco de dados MySQL. O exemplo abaixo teve alguns parâmetros adaptados:
Como a configuração especifica um arquivo com variáveis de ambiente, também precisamos dele, o stack.env, com o conteúdo abaixo.
O Portainer espera que o arquivo seja especificado com esse nome no yml, porque é o nome do arquivo que ele forma a partir das variáveis que são fornecidas. O arquivo para upload pode ter qualquer nome.
Todas as variáveis estão no stack.env. O Portainer não resolve variáveis no arquivo .yml, então todas precisam ser especificadas no stack.env ou no próprio .yml. Isso levou a variáveis com valores redundantes no stack.env
Pela mesma questão acima, o teste do banco de dados foi removido.
Volumes docker foram especificados em vez de caminhos para pastas no host.
Para uma implantação desse tipo no Portainer, vá na seção Stacks. Lá é possível fazer upload dos arquivos ou colar o conteúdo no editor web.
O GLPI leva um tempo após a inicialização do contêiner para ser instalado e ficar disponível na porta mapeada, nesse caso 8080. O MySQL gera uma senha aleatória para o usuário root, que você pode obter com:
Voltando ao Metabase: a implantação do Metabase abordada armazena as configurações em um banco de dados H2, no volume do próprio contêiner, sem nenhum volume persistente configurado. Ou seja, ao fazer uma atualização – que é feita por remover e adicionar um novo contêiner, todas as configurações, dashboards e conexões com bancos de dados seriam excluídos.
Para uso em produção, o metabase precisa ser combinado com um banco de dados para produção, como PostgreSQL. Abaixo, um exemplo de configuração em formato .yml para implantação: